

We're still in the steam-powered days of machine learning
We're still in the steam-powered days of machine learning
ML platforms are complicated, unique, and, so far, hard to reproduce


The reveal of the ridiculous Cybertruck design last week made me curious about the history of cars. If you look at pictures of cars from the early days (as I, a Normal Person, did last Friday night), you’ll see some insane ideas. Before we got to the Ford Model-T that standardized car production, people iterated on a ton of crazy stuff. For example, here is a steam car from the 1700s:

By Photo et photographisme © Roby. Grand format sur demande - own work. Avec l'aimable permission du Musée des Arts et Métiers, Paris., CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=41639
Here’s a steam-powered bus.

Here’s an electric-powered tricycle:

And here is the creme de la creme, the Oruktor Amphibolos, hailing from my own fair city of Philadelphia,
built by Evans for the Philadelphia Board of Health as a solution to the Board’s concerns about dredging and cleaning the city’s dockyard and removing sandbars. It could drive along on four wheels or steam down the river using its rear-mounted paddle

It took some time for people to experiment and agree on what a car even was, what features it had, and how it needed to work. For example, for a long time in the beginning, quite a few cars ran on steam, until gasoline began to overtake them (thanks in part to Henry Ford’s standardization of the assembly line, which made non-gasoline cars harder to produce. ) Eventually, all the cars standardized to the form we know today: a closed car, powered by gasoline, with four wheels, four windows, seating 4-8 people. No paddles. Even the godawful Cyberthing follows this model.
Today, when we talk about modern technologies, machine learning comes up pretty frequently as the future-iest of them all. It’s often seen as an exciting (ahem) vehicle to move people to the future - to predict cancer, to improve prisons, to iterating on French fries.
But, we are still very much in the weird, early steam-powered tricycle days of machine learning.
What prompted me to think about this was that earlier this month, Lyft released an open-source machine learning platform, called Flyte. Flyte is a an:
end-to-end solution for developing, executing, and monitoring workflows reliably at scale.
Let’s back up a step.
What do we mean by machine learning platforms? Simply put, they’re a systematized, automated way to take raw data, transform it, run a model on it, and show some sort of results that lead to decision-making, either for internal or external customers.
Let’s start with some examples.
Serving Netflix recommendations is a machine learning platform. The Facebook News Feed incorporates machine learning. Amazon recommendations. On and on. Anything that serves you personalized content online is (likely) powered by some kind of machine learning.
On the webpage, the creators of Flyte say that it currently powers Lyft Pricing, which generates the ride price you see when you pull up the app. For example, here’s a price estimate from me to Suraya, a very tasty Middle Eastern restaurant in Philadelphia that has delicious hummus, but almost zero parking spaces nearby.
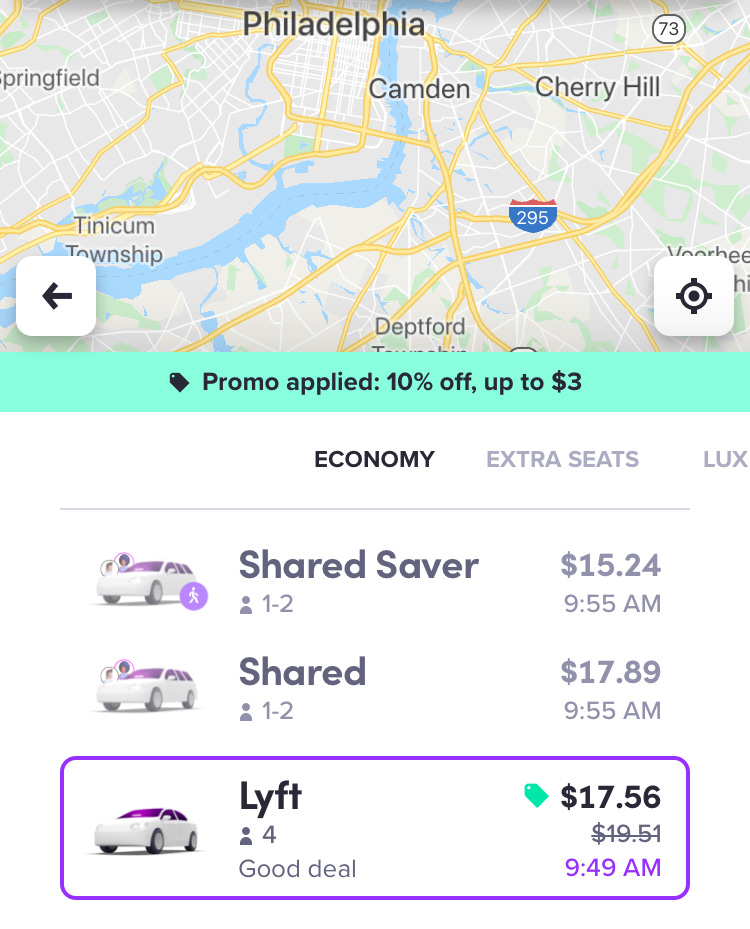
When I pull it up, The price the app gives for a single-passenger Lyft is $17.56. It’s just a single number. But to pull that number and display it the moment I need a Lyft takes a lot of work.
To start with, let’s think about some of the things we’d need to get an accurate price estimate for an on-demand car, given that we know where all the other cars in the app are (actually, a variant of this is probably an interview question that Lyft asks).
Here are some of the things that go into figuring out what is known in data science lingo as dynamic pricing. Lyft’s own site says:
Our goal at Lyft is to connect you with best-in-class service at an affordable price when and where you need it. To achieve this goal, prices for rides are dynamically calculated based on a variety of factors including route, time of day, ride type, number of available drivers, current demand for rides, and any local fees or surcharges.
So here we have a bunch of variables that we need to collect to make a model:
time of day
length of route
ride type
number of drivers available
current driver demand
local fees
And here’s what else I think goes into it (I’m completely spitballing here based on my previous transportation/data science work. Lyft people, feel free to email me and tell me I’m wrong (and maybe send a free coupon for 15% off my next ride):
geographic location (Philadelphia or Pasadena?)
difficulty of route (Highway or city traffic?)
weather
Some other things that Lyft may use internally but won’t tell you about because it might get bad press (i.e. driver rating, rider rating, how many Ubers are potentially in the area, and more. )
Collecting all this data is not easy, particularly when you need to update it in real-time. So Lyft might have a graph database that has calculations of coordinates and distances, driver data, current driver demand and rider data. It needs to get all of this data into one place, crunch it through an algorithm that generates a price, and spit that price out to the front-end web app.
This is a really, really simplified view of what’s going on (and almost completely illegible, but hey, they pay me to build these platforms, not draw them)

We have the initial data sources: a graph database updating driver location among route ride segments, maybe a graph database of pricing based on those route segments, a table full of driver data (ratings, reviews, car make, etc.) and one of rider data (ratings, etc.).
All of this is an enormous amount of data and needs to be consolidated and moved into one place. Some of it will be streamed through pipelines like Kafka, some will be through web service requests, some will be loaded directly from a database.
All of this data is then aggregated in a centralized machine-learning store, which then generates a clean dataset for modeling. That dataset is plugged into a working statistical model, which trains and picks the most important features (the variables that make price go up or down), tunes hyperparameters (the metadata about the model, such as how many times you want to run it), and, as a prediction, spits out the number $17.56.
That number then needs to travel via to the iOS app, where we, the end consumer, finally see it.
Phew!
That’s a lot of work. And, what I’ve described is basically an idealized state, where you have everything functioning. If you really want to torture yourself, do an image search for “machine learning platform architecture” and see how complicated some of the architectures are.
In reality, there are so many problems that can arise in machine learning platforms. This Google paper, “Machine Learning: The High Interest Credit Card of Technical Debt” — which is a classic and I think everyone working with data should read — describes many of them.
Just look at Adam’s tweet creating an idealized outline of a book that would cover all the steps of getting machine learning into production - look at how many things can break!
Data Problems
First, your data sources might start producing incorrect data. Or, the data might be dirty: for example, what if your system has Philadelphia as Phla, or Phila, or Philly? Or all four! How do you tie that to other data? Your data might be in different formats: Some in JSON from web services,some in CSV outputs from SQL query results, some in serialized, compressed formats like Avro which then needs to be converted to Parquet, and on and on.
Remember that data cleaning makes up the majority of data work.

Model Problems
Then, you might get something called model drift:
Nothing lasts forever. Not even a carefully constructed model on mounds of well-labeled data. Its predictive ability decays over time. Broadly, there are two ways a model can decay. Due to data drift or due to concept drift. In case of data drift, data evolves with time potentially introducing previously unseen variety of data and new categories required thereof. But there is no impact to previously labeled data. In case of concept drift our interpretation of the data changes with time even while the general distribution of the data does not
Or, you might have incorrect model feedback loops, which is what happens when you end a statistical experiment too early and come to the wrong conclusion.
Or, perhaps the model is the wrong one for the shape of the data and you need to cycle through a couple different options.
Software Problems
Then, on top of the data issues there are your garden variety software engineering issues: data not getting ingested quickly enough, data feeds breaking, data incompatibility issues between formats, data warehousing problems, web service connection issues, configuration issues, and if you’re on a cloud platform, firewall and permissions issues between all the ways these services connect.
(Most of my career in machine learning so far has been spent fixing data compatibility and connection issues (and troubleshooting AWS Lambdas.))
I’ve only really scratched the surface here.
Today’s ML Platforms
All of these issues is something the concept of a machine learning platform hopes to solve. What you’re doing when you develop a platform, is you, in theory, wrap all of that stuff together into a single system where compatibility is not an issue and there is no messy glue code.
Essentially, you’re taking all the parts you need for the car to function - tires, windows, combustion engine, windshield wipers, and putting it together into the monstrous Cybertruck form.
Today, there are lots of machine learning platforms that are popping up aside from Flyte. Uber, Lyft’s direct competitor, has Michelangelo. Facebook has FBLearner Flow. Databricks has MLFlow. There’s Sagemaker on AWS, Azure, BentoML, and CometML and many, many more.
Some, like Michelangelo, Stripe’s Railyard, and Twitter’s Cortex, are proprietary. Some, like BentoML and Flyte are open-source. Some, like CometML are SaaS products, some, like Flyte are self-hosted. Some focus on the actual modeling process, some focus on hyperparameter tuning, some focus on algorithms, some focus on data ingest and cleaning, some focus on visualization.
There really is no good, generalized single system of best practices for creating machine learning platforms. There’s not even a textbook on it. (Other than Designing Data-Intensive Applications, which is good but doesn’t necessarily fit the bill.)
Much like the steam-powered tricycle, each machine learning project is beautiful and weird and inefficient in its own way. Every company has its unique set of needs, stemming from the fact that each company’s data and business logic run differently. In a recent Hacker News threads on how models are deployed in production, there were over 130 different answers, ranging from using scikit-learn, to Tensorflow, to pickling objects, to serializing them, to AWS Lambdas, to Kubernetes, to even C#.
The other amazing thing about machine learning platforms is that none of this stuff is new: people have been trying to build machine-learning type cars for over 20 years now.
Just take a look at this Usenix paper FROM 2002, trying to analyze logs:
Server systems invariably write detailed activity logs whose value is widespread, whether measuring marketing campaigns, detecting operational trends or catching fraud or intrusion. Unfortunately, production volumes overwhelm the capacity and manageability of traditional data management systems, such as relational databases. Just loading 1,000,000 records is a big deal today, to say nothing of the billions of records often seen in high-end network security, network operations and web applications. Since the magnitude of the problem is scaling with increases in CPU and networking speeds, it doesn't help to wait for faster systems to catch up.
This paper discusses the issues involving large-scale log management, and describes a new type of data management platform called a Log Management System, which is specifically designed to cost effectively compress, manage and analyze log records in their original, unsummarized form.
We’re not any closer to a complete, efficient, generalizable solution now (although we sure are using a lot of Kubernetes these days, including in Flyte). Yet.
So what?
All of this is to say, these systems that are serving us music recommendations, books we’d like to buy, News Feed items from friends, Airbnb, whatever, are still sometimes very fragile, very brittle, and very much experimental (although there are some, as Normcore readers can attest, that are generally very good.)
What does this mean? It means, first, don’t believe the hype that any one single machine learning platform will solve your needs. And second, be very, very careful with the high-interest credit card of technical debt: machine learning. Make sure that if you or your company has or is thinking about such a system, that it’s very carefully monitored, tagged, and that results are constantly evaluated, and that it has tests.
And, if you’re a consumer, think about all the stuff that has to happen for a recommendation or action to make its way to you, and be skeptical. The system is not always right. We are still very much in the early, experimental days of what machine learning platforms need to be, and don’t let anyone tell you different.
But, does this mean you should panic and that machine learning is worthless? Also absolutely not. (This is Normcore, after all.) There are plenty of platforms that work well, that are stress-tested, and reasonable. They just probably won’t work exactly the same way for your company.
But we as an industry need to keep trying, experimenting, and, most importantly, documenting and sharing these systems, how to run them, and their results publicly.
Because, if we don’t iterate, how else are we ever going to get from a steam-powered paddleboat, to a Tesla?
Art: Car Clothing, Dali, 1941
What I’m reading now:
Love, love, love this article explaining “moral grandstanding” - why social media is toxic
The data enrichment industry, if you want to depress yourself this Thanksgiving.
Everyone should learn Latin (not biased at all here, having taken 4 years of it.)
“Am I the asshole for regifting my kids their tablets for Christmas?”
Delivering cows in Yakutia
How do you design a social media site to avoid misinformation?
Best 2019 Thanksgiving tweets
About the Newsletter
This newsletter is about issues in tech that I’m not seeing covered in the media or blogs and want to read about. It goes out once a week to free subscribers, and once more to paid subscribers. If you like this newsletter, forward it to friends!
Select previous free Normcore editions:
What’s up with Russia’s Internet · I spent $1 billion and all I got was this Rubik’s cube· Die Gedanken sind frei · Neural nets are just people· Le tweet, c’est moi· The curse of being big on the internet· How do you like THAT, Elon Musk?·Do we need tech management books? · Two Python Paths
Select previous paid Normcore editions:
Imgur is bad now · Eric Schmidt and the great revolving door· No photos please · Deep thoughts of Cal Newport
About the Author:
I’m a data scientist in Philadelphia. Most of my free time is spent wrangling a preschooler and an infant, reading, and writing bad tweets. I also have longer opinions on things. Find out more here or follow me on Twitter.